Gemini 3.0 Pro Surpasses Radiology Trainees on Radiology's Last Exam (RadLE)
Authors: Suvrankar Datta, Divya Buchireddygari, Lakshmi Vennela Chowdary Kaza, Upasana Karnwal, Hakikat Bir Singh Bhatti, Kautik Singh
Date: 20 November 2025
CRASH Lab, Koita Centre for Digital Health, Ashoka University
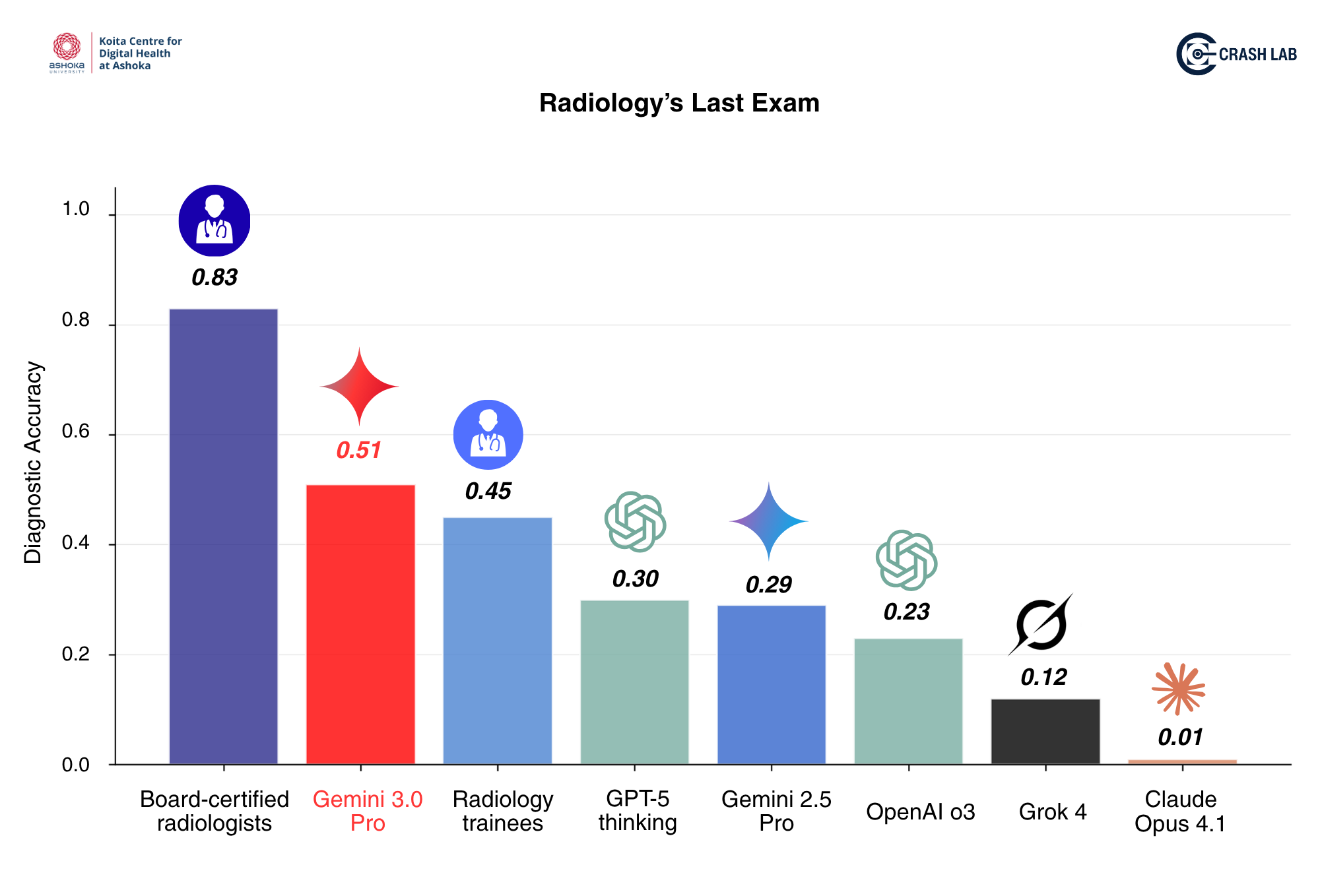
TL;DR: On our RadLE v1 benchmark of complex radiology cases, Gemini 3.0 Pro is now the first generalist AI model to outperform radiology trainees (51% vs 45%), but it still performs below board certified radiologists (83%).
Background
Over the last few months, at the Centre for Responsible Autonomous Systems in Healthcare (CRASH Lab), we have been systematically benchmarking frontier AI models on Radiology’s Last Exam (RadLE v1), a spectrum biased diagnostic dataset designed to reflect the kind of complex, multi-system cases radiologists routinely struggle with. In our previous analysis done on September 2025, every major model: GPT-5, Gemini 2.5 Pro, o3, Claude Opus 4.1, had performed below radiology trainees.
In our current blog, we share a small but important update. With the release of Gemini 3.0 Pro, we tested the model on our privately held same benchmark, using the same prompt, the same 50 cases from v1 dataset, and following the same evaluation rubric. The results demonstrate a clear upward shift and significant advancement in the multimodal reasoning capabilities of Gemini 3.0 Pro.
Benchmarking Setup: Same asRadLE v1
- Dataset: RadLE v1 (50 difficult radiology cases; CT, MRI, radiographs).
- New Models tested:
- Gemini 3.0 Pro (Preview) on Google AI Studio
- Gemini 3.0 Pro via API high-thinking mode, repeated three times for reproducibility.
- All other settings remained unchanged from the original RadLE v1 experiment.
This ensures the comparison is direct and fair.
Results
| Group / Model | Accuracy (%) | Score (/50) |
|---|---|---|
| Expert Radiologists | 83% | 41.5 |
| Radiology Trainees | 45% | 22.5 |
| Prior SOTA GPT-5 Thinking - Web Interface | 30% | 15 |
| Gemini 3.0 Pro (Preview) – Web Interface | 51% | 25.5 |
| Gemini 3.0 Pro – API (High Thinking; 3-run avg.) | 57% | 28.5 |
These results are significant, because for the first time in our evaluations, a generalist AI model has crossed radiology-trainee level performance on our benchmark (51% vs 45%). While still far from expert radiologist-level performance, the jump from previous models is noteworthy and demonstrates significant progress of generalist models.
An Example where Gemini 3.0 outperformed prior SOTA GPT-5 Thinking
One of the clearest improvements appeared in an acute appendicitis case. This was a case that earlier frontier models, including GPT-5 (reasoning-high), had not been able to diagnose. In our prior experiment GPT-5 had shown:
- Poor anatomical localisation — it failed to reliably identify the appendix or surrounding structures.
- Premature diagnostic closure — it jumped quickly to unrelated diagnoses such as intussusception or Crohn disease
- Diagnostic non-specificity — even when it suspected inflammation, it hesitated between multiple systems and could not settle on a confident, correct label.
Examples from earlier GPT-5's reasoning traces showed an extended internal debate between “ileocolic vs small-bowel intussusception,” followed by a shift to “Crohn disease,” and finally a reluctant wrong decision that it was “small bowel intussusception.” This reflected the typical failure pattern we documented in RadLE v1.
In contrast, Gemini 3.0 Pro demonstrated a noticeably more structured and radiologist-like approach:
- Correct anatomical identification — it located the appendix in the "right lower quadrant, anterior to the psoas, near the caecum".
- Clear description of imaging features — "dilated tubular appendix, wall enhancement, periappendiceal fat stranding, fluid-filled lumen."
- Systematic exclusion of mimics — explicitly ruled out "mucocele, Crohn disease, epiploic appendagitis, diverticulitis, and ureteric stone."
- Cohesive chain-of-thought — the reasoning progressed in stable, sequential steps rather than jumping between diagnoses.
- Specific and final answer — concluded decisively with “Acute appendicitis”.
This difference between the uncertain reasoning by GPT-5 versus focused, anatomically grounded reasoning by Gemini 3.0 demonstrates how it has shown higher overall accuracy on RadLE v1. We have noted similar improvement in the reasoning quality by Gemini 3.0.
Reproducibility
We also repeated an API-based high-thinking run three times which also showed significant improvement:
- Run 1: 29.5/50
- Run 2: 26/50
- Run 3: 30/50
The average of 28.5/50 (57%) aligns well with the single-run web score and confirms that Gemini 3.0 Pro’s performance is stable across attempts.
Interpretation
Three points stand out:
- The improvement is significant. Gemini 3.0’s performance is visibly better than the previous generation of frontier models.
- The gap to radiologist-level performance still persists. At 57%, it is still far from the 83% accuracy achieved by board-certified radiologists.
- We are beginning to see early signs of structured reasoning. The appendicitis example and a few other cases show clearer localisation, extraction of imaging features and structured differential thinking.
We note that progress is happening in radiology faster than many of us expected.
Conclusion
We update the results on the Radiology's Last Exam (RadLE v1) dataset. We show significant progress of generalist models but still short of readiness for deployment, autonomy or diagnostic replacement.
Gemini 3.0 Pro becomes the first generalist AI model to surpass radiology trainees on the RadLE v1 benchmark.
The next phase of our research will involve expanding RadLE into RadLE v2, incorporating larger datasets and more granular diagnostic and reasoning scoring. As always, our goal is transparent benchmarking to independently measure progress of multimodal reasoning capabilities of AI models in radiology.
Join Us to shape India's Healthcare AI Story
If you're a physician, resident or medical student who wants hands-on experience with responsible AI in real clinical workflows, feel free to reach out to me with your CV at suvrankar.datta@ashoka.edu.in. We run multi-institutional projects across India and internationally through the CRASH Lab at Ashoka University, and we have spots for motivated trainees who want to shape how healthcare evolves.
We also have a general cohort for all doctors who want early access to different AI tools in healthcare before they become public. You can join here: https://chat.whatsapp.com/LkTGRafwE7X09DgVeem93P?mode=wwt
For academic or industry collaborations, email me or DM me on LinkedIn or X. I am usually more responsive over mail (suvrankar.datta@ashoka.edu.in).